
You no longer need to sit in front of a microphone for hours to produce a podcast in your own voice. Voice cloning technology has matured to the point where 60 seconds of clean audio is enough to train an AI model that speaks for you — capturing your unique tone, pacing, and personality. This guide explains exactly how voice cloning works, what you need to get started, and what podcasters need to know about quality, ethics, and platform use.
What Is Voice Cloning?
Voice cloning is the process of using artificial intelligence — specifically deep learning models trained on speech — to replicate a specific human voice. Unlike generic text-to-speech (which uses a pre-built AI voice), voice cloning creates a personalized voice model derived from a real person's actual recordings.
The result is a voice that can read any script and sound like the original speaker: same pitch, same rhythm, same accent, same verbal quirks. Modern cloning systems capture not just the basic acoustic characteristics of a voice but also its prosodic patterns — the natural rises and falls, the pauses, the emphasis — that make a voice sound distinctly human and distinctly yours.
Voice cloning is one of several key features of modern AI podcast generators. Platforms like PodGorilla offer voice cloning as part of an end-to-end workflow: upload your audio sample, generate a script from any URL or PDF, and produce a full podcast episode narrated in your cloned voice.
How Voice Cloning Works Technically
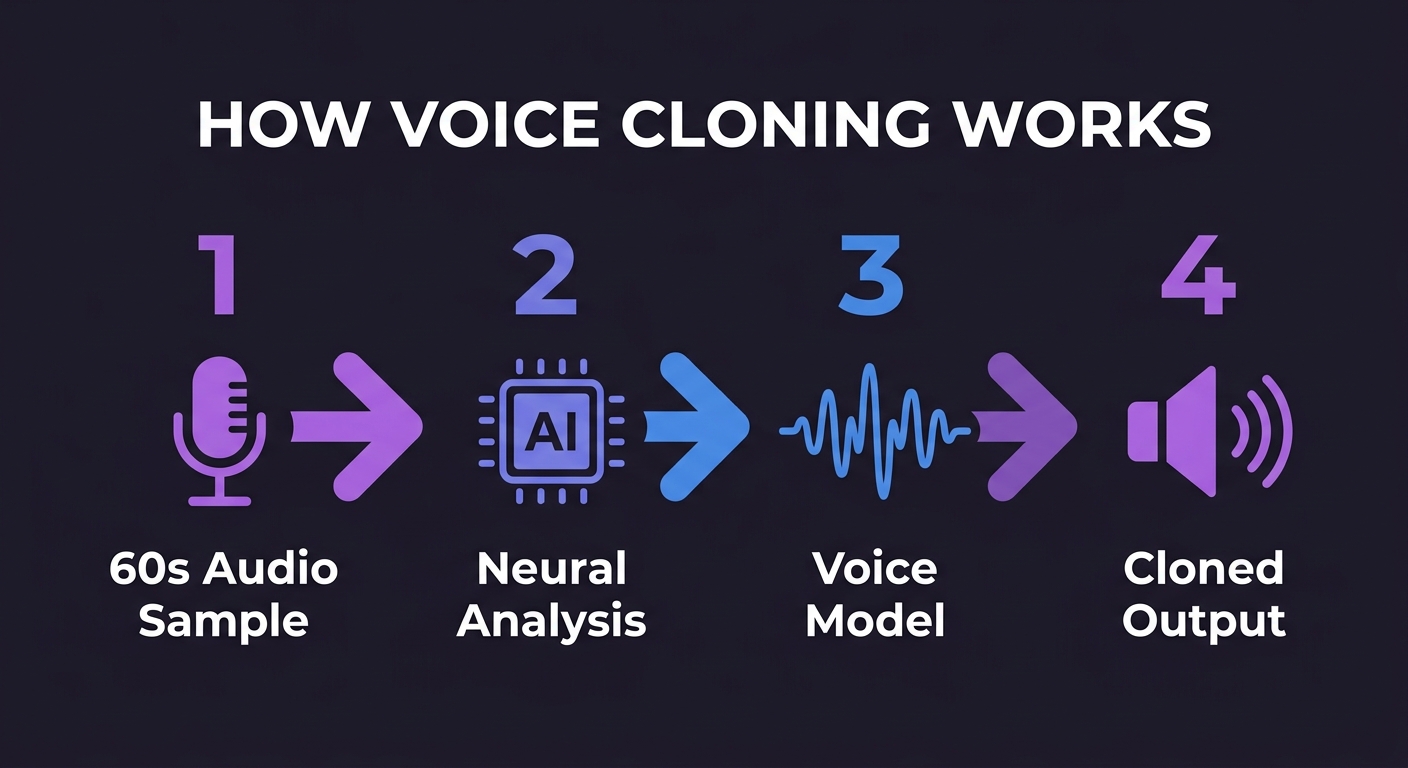
Voice cloning relies on a branch of machine learning called neural voice synthesis, combined with a technique called few-shot learning. Here's how the process works at a technical level:
Step 1: Audio Analysis
The system ingests your audio sample and converts it into a spectrogram — a visual representation of frequency over time. This captures not just pitch and volume but the full timbral "fingerprint" of your voice: the resonance of your vocal tract, the way you articulate consonants, the micro-timing of your speech.
Step 2: Speaker Embedding
A neural encoder network (similar to the speaker encoder used in Google's Transfer Learning from Speaker Verification research) compresses your voice's characteristics into a compact numerical vector called a speaker embedding. This embedding is essentially a mathematical fingerprint of your voice.
Step 3: Voice Synthesis with Your Fingerprint
When you enter new text, the TTS synthesis model — typically a neural network like a modified Tacotron or VITS architecture — uses your speaker embedding to generate speech audio that matches your voice profile while speaking the new words. The output is then processed through a vocoder (like HiFi-GAN) to produce high-fidelity audio.
Step 4: Few-Shot Learning
The term "few-shot" refers to the model's ability to adapt to a new voice from very limited samples — as few as 60 seconds. This is in contrast to traditional voice synthesis, which required hours of recorded speech. Modern few-shot voice cloning models like those used in enterprise-grade platforms can achieve convincing clones from short clips because they've been pre-trained on thousands of diverse speaker voices, making them highly adaptable.
What You Need to Clone a Voice
Getting started with voice cloning for podcasting requires surprisingly little. On PodGorilla, the requirements are minimal:
- 60 seconds of clean audio — recorded in a quiet environment with no background music, echo, or crowd noise. A phone recording in a quiet room is sufficient.
- Clear, natural speech — read a paragraph from a book, record a casual monologue, or use an existing voice memo. The content doesn't matter; the acoustic quality does.
- Consistent volume — avoid whispering or shouting. Normal conversational volume produces the best clone.
- A single voice only — don't include other speakers in the sample. The model needs to learn one voice at a time.
Once uploaded, PodGorilla processes the audio and makes your cloned voice available across all episodes — so every podcast you generate, regardless of the script or topic, is narrated in your voice.
Use Cases for Podcasters
Voice cloning unlocks several powerful workflows for podcast creators:
Personal Brand Consistency
The most common use case. If you run a personal brand podcast — a thought leadership show, a coaching series, a niche commentary podcast — listeners expect to hear your voice. Voice cloning lets you produce episodes at scale without hours of manual recording. You write (or AI-generates) the script; your cloned voice reads it.
Multilingual Content
Advanced voice cloning platforms can use your voice model to generate speech in languages you don't speak. This means your podcast can reach Spanish, Portuguese, French, or German-speaking audiences while still sounding like you — not like a generic translator. For creators targeting global audiences, this is transformative.
Consistent Narrator Voice
For serialized storytelling, educational content, or branded shows with a "narrator" persona, voice cloning ensures every episode sounds like the same person regardless of who writes the script. This is especially valuable for agencies producing podcasts for multiple clients under a consistent brand voice.
Accessibility and Efficiency
Creators with speaking challenges, disabilities, or simply very busy schedules can maintain an active podcast presence without the physical demands of regular recording sessions. The AI reads; you direct.
Voice Cloning Quality: What to Expect
Voice cloning quality varies significantly based on the platform, the quality of your source audio, and the length of your sample. Here's a realistic overview of what modern cloning achieves:
| Provider / Platform | Min. Audio Required | Languages | Quality Level | Best For |
|---|---|---|---|---|
| PodGorilla | 60 seconds | 30+ | Broadcast-grade | Full podcast episodes, personal brand |
| ElevenLabs | 1 minute | 30+ | Broadcast-grade | Short-form audio, voiceovers |
| Resemble AI | 3–5 minutes | 20+ | High | Enterprise, custom integrations |
| Murf AI | 5+ minutes | 20+ | High | Presentations, e-learning |
| Descript Overdub | 10 minutes | English only | High | Podcast editing corrections |
The key quality factors are: the naturalness of prosody (does it sound like a real person or a robot reading?), the accuracy of timbre replication (does it sound like you specifically?), and artifact frequency (how often does it produce mispronunciations or unnatural pauses?).
"In evaluations conducted in 2024, AI-generated speech from leading voice cloning platforms was rated as 'human-sounding' by listeners more than 85% of the time when the source audio quality was high. The gap between synthetic and human voice is now primarily perceptible to trained audio professionals, not general audiences."
— IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024
Ethical and Legal Considerations
Voice cloning is a powerful technology and, like all powerful technologies, it comes with responsibilities. Here's what podcasters and content creators need to know:
Consent Is Non-Negotiable
You should only clone your own voice, or the voice of someone who has given explicit written consent. Cloning another person's voice without permission is unethical and increasingly illegal. Several U.S. states (including Tennessee's ELVIS Act) and the EU's AI Act impose legal restrictions on unauthorized voice cloning.
Disclosure to Audiences
Major podcast platforms including Spotify and Apple Podcasts now require disclosure when AI-generated voices are used in content. Best practice is to include a disclosure in your episode description (e.g., "This episode's narration was produced using AI voice technology."). This protects you from platform policy violations and builds audience trust.
Platform Compliance
Use voice cloning only through licensed platforms that enforce consent verification. PodGorilla requires you to affirm that you have rights to the voice being cloned before your model is activated. This protects both you and the platform from misuse.
Deepfake Risk Awareness
A cloned voice model, in the wrong hands, could be used to impersonate the original speaker. Keep your voice model private and only share it through trusted, access-controlled platforms. Never publicly export or distribute a raw voice model file.
How to Start Voice Cloning for Your Podcast
If you're ready to use your own voice across AI-generated podcast content, the process on PodGorilla takes under five minutes:
- Record 60 seconds of clean audio on your phone or computer — read aloud naturally, in a quiet room.
- Upload the file in your PodGorilla account under Voice Settings → Clone My Voice.
- Confirm consent and wait 2–5 minutes for the model to process.
- Select your cloned voice when creating any new podcast episode.
- Generate your script from any URL, PDF, YouTube link, or topic — and your cloned voice reads it.
You can combine voice cloning with any of PodGorilla's 12+ podcast styles — solo commentary, interview format, storytelling — and export in audio or video format for distribution to all platforms. Start for $1 →
For a broader look at producing episodes without traditional recording, see our guide: how to start a podcast without recording.
Frequently Asked Questions
What is voice cloning?
Voice cloning is an AI process that creates a digital replica of a specific person's voice from a short audio sample. The resulting voice model can speak any text in the original speaker's tone, accent, and cadence. It uses neural voice synthesis and few-shot learning to achieve high fidelity from as little as 60 seconds of source audio.
How much audio do I need to clone a voice?
Modern platforms require as little as 60 seconds of clean audio. PodGorilla's voice cloning works from a minimum of 60 seconds. Longer samples (2–5 minutes) can improve accuracy, but the improvement is marginal with current generation models. The most important factor is audio quality — clean, quiet, consistent volume — not length.
Is voice cloning legal?
Cloning your own voice or the voice of someone who has given explicit consent is legal in most jurisdictions. Cloning another person's voice without permission is increasingly illegal — the U.S. VOICE Act and several state laws (including Tennessee's ELVIS Act) prohibit unauthorized voice cloning. Always use a licensed platform that enforces consent policies.
Do I need to disclose that my podcast uses a cloned voice?
Yes. Spotify, Apple Podcasts, and most major platforms require disclosure when AI-generated or cloned voices are used in content. Best practice is to add a brief disclosure in your episode description and show notes. This is also good for audience trust — many listeners appreciate the transparency.
Can voice cloning replicate my accent and speech patterns?
Yes. Modern voice cloning captures not just pitch and timbre but also accent, speech rhythm, and verbal patterns. If you have a distinctive regional accent or speaking style, the clone will reflect it — this is actually one of the key advantages of voice cloning over generic AI voices for personal brand podcasting.
Can I use a cloned voice for a podcast in a different language?
Many advanced platforms support cross-lingual voice cloning, where your voice model is used to generate speech in languages you don't natively speak. PodGorilla supports 30+ languages with voice cloning. The accent transfer may not be perfect across very different language families, but intelligibility and voice likeness are generally preserved.
